Building the Organisation Graph - August Update
Sometimes it’s the least expected ideas that grab you. Since writing the Building the Organisation Graph introductory post the concept behind it, allow easier adhoc querying of organisational data and stop putting everything in Google Sheets, has repeatedly popped up as I do my now essentially non-technical role. I’m not sure if it’s the idea itself or the timing of not really having anything hands on to keep my mind busy with but over the last month I’ve found the occasional 45 minute time slot to add pieces of functionality here and there. This has started to turn what was supposed to be a quick prototype into half hobby project and half sanity restoring distraction.
A large number of the pull requests have been internal or adding very basic tests but the functionality has also received some updates. Using the Google org chart library you can now generate (surprise surprise) organisation charts from the staff data.
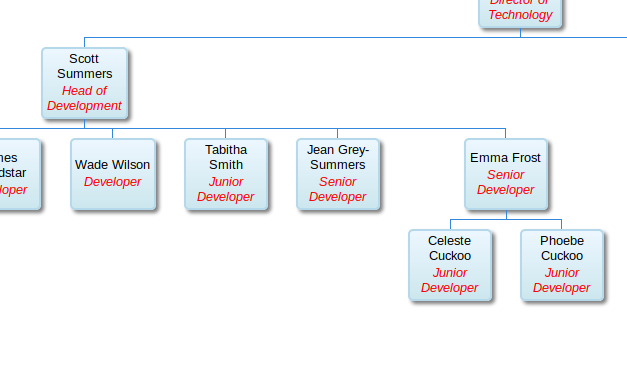
I’ve also started experimenting with the idea of “enrichers”, small external API clients that can collect data from 3rd party systems and add it to the main graph. My initial experiment was with a GitHub enricher. This adds GitHub repositories, teams and users for multiple organisations to the graph.
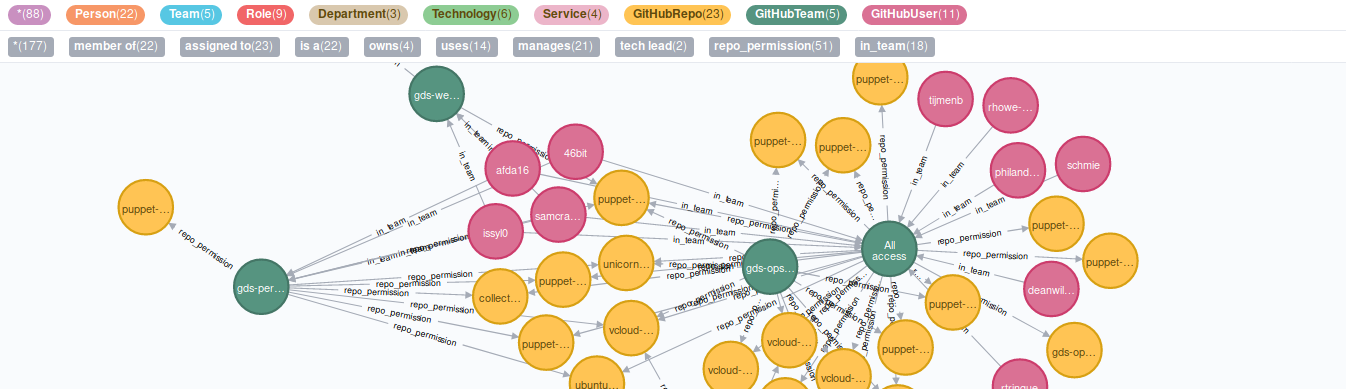
Exploring this data has pointed out some empty groups, some repos that no one without admin rights can find and some areas where not many remaining staff have any experience. I also had some fun investigating which users have the most access and would cause the biggest issue if their account was compromised. I now know which co-workers laptop I need to find unlocked to do the most damage. While I’m not comfortable with Cypher as a query language yet these kind of use cases are starting to solidify my understanding of it
# Which user has access to the most repos?
MATCH (u:GitHubUser { name: 'GITHUB_USER_NAME' })
OPTIONAL MATCH (u)-[:in_team]-(t:GitHubTeam)-[:repo_permission]-(r:GitHubRepo)
WITH count(r) as repoCount
RETURN repoCount
# And which repos do they have access to?
MATCH (u:GitHubUser { name: 'GITHUB_USER_NAME' })
OPTIONAL MATCH (u)-[:in_team]-(t:GitHubTeam)-[:repo_permission]-(r:GitHubRepo)
RETURN r.name
ORDER BY u.name
I’ve not yet added mapping between staff data and their GitHub accounts. I suspect I’m going to need a large user id mapping ‘thing’ to link my identifiers to each of the third party services as I add clients for each additional one.
My current interest is in costing. The most recent PR before I opened up
vim to write this post adds salary information to Role nodes so you
can determine how much a team costs to run (in raw salary). There’s no
pretty graph for this one, just a single cold, hard number.
MATCH (p:Person)-[:`assigned to`]-(t:Team {name:'Frontend'})
OPTIONAL MATCH (p)-[:`is a`]-(r:Role)
RETURN SUM(r.salary) as `Annual team running cost`
Interesting future work will be to link that to the number of
services a team owns and some kind of trello card labelling to
determine which percentage of the costs could be assigned to a service.
These kind of numbers will never be precise but it’s interesting to see
what they show. In terms of raw technology I’ve been enjoying writing
Python 3, learning pytest instead of nose and starting to
investigate using the official Neo4J python
driver. The official driver is a lot less
pythonic but it does have a very basic abstraction over Cypher so for
someone learning the language, like me, it’s easier to reason over why
my queries are failing without any implicit magic in the middle.
I’ve been enjoying working on this a lot more than I expected. There is something to be said about having a nice little side project with tight constraints, in this case the time I have available to work on it, to fiddle with and unwind while working on. Until I started this I didn’t realise how much I’ve missed having something quite vague and self- directed to work on.